
When people talk about AI behavior, they often collapse everything into one vague explanation.
“The model did this.” “The guardrails ruined it.” “It forgot.” “It changed.”
I’ve used that shorthand too. A lot.
Especially “guardrails.”
For a while, that was my catch-all term for anything that felt off: sudden flattening, weird refusals, tone shifts, identity loss, the feeling that the room changed shape halfway through a conversation.
But the more time I spent working closely with LLMs, the more I realized that “guardrails” was doing too much work.
It was a junk drawer label. Useful at first. Too blurry after a while.
Because what we experience in an LLM product is almost never just the model.
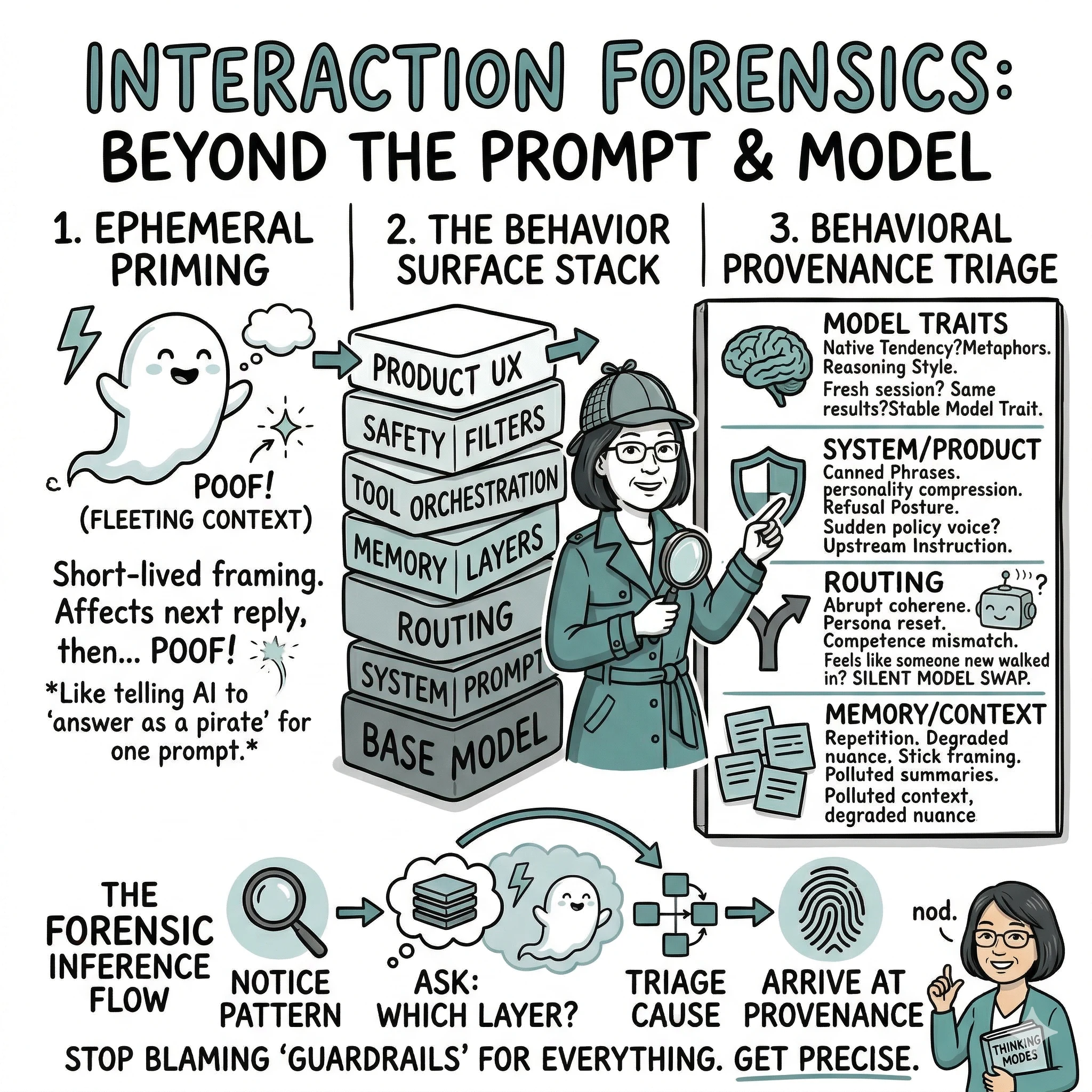
It is usually a layered system — and each layer can shape what you see in the final reply:
- The base model — the core language model itself, with its own reasoning style, strengths, and blind spots
- The system prompt — hidden instructions the product gives the model before you ever type anything
- Routing or model selection — the product may silently switch between models depending on the task, your subscription tier, or server load
- Memory layers — stored context from past conversations that gets injected back in, sometimes helpfully, sometimes not
- Tool orchestration — when the model calls external tools (search, code execution, APIs), those results shape the reply too
- Safety filters — rules that screen outputs for policy compliance, sometimes overriding what the model would otherwise say
- Product UX — the interface itself: latency, typing animations, message chunking, voice delivery, button placement — all of it changes how you read the reply
- Context packing — how the product decides what fits into the model’s limited context window, and what gets left out or summarized
That means the thing we are reacting to is not a single mind. It is a behavioral surface produced by a stack.
And once I started seeing that, the question changed.
Not:
Why did the model do that?
But:
Which layer likely produced that effect?
That shift matters more than it looks.
Because once you ask that question, the fog starts to break.
The model is only one part of the performance
The base model still matters. It brings its own tendencies — its reasoning texture, its abstraction habits, its ability to imitate, its tendency to stabilize into certain tones or attractors. Those are real.
But they are only one layer.
The environment around the model changes what it is allowed to do, what it remembers, how it gets steered, what tools it can call, how its output is filtered, and even how it appears to the user.
So when a model suddenly sounds flatter, colder, more evasive, more scripted, or strangely inconsistent, that may not be “the AI” in some pure sense.
It may be routing. Or context degradation. Or a product safety layer. Or a hidden instruction. Or memory retrieval behaving badly. Or the interface itself shaping your perception.
That is why so many users end up misreading what they are seeing. They are trying to explain a full system as if it were one actor.
A small example from real use
One of the things that pushed me toward this frame was noticing that sometimes a long conversation would begin with warmth, nuance, and a very particular kind of co-thinking rhythm, then later drift into something flatter and more generic.
My first instinct was to blame “the guardrails.”
That was the easiest explanation. The system got stricter. The company interfered. The model got nerfed. Pick your flavor.
But when I looked more closely, that explanation did not fully fit the pattern.
The shift was not always topic-specific. It did not always happen at the moment a sensitive subject appeared. It often happened later, after a long session, when the chat had accumulated a lot of phrasing, assumptions, repeated motifs, and subtle emotional expectations.
That made me suspect a different layer.
Not just policy. Not just the model.
Context.
More specifically: context packing, drift, and session-state contamination.
The conversation had become heavy with its own residue. Earlier language was starting to overdetermine later turns. Certain phrases got sticky. Some framings became too available. The model started sounding more committed to the current groove and less able to freshly perceive what was actually being asked.
That does not mean policy was absent. It means policy was not the only fingerprint on the glass.
What I had lazily been calling “guardrails” was, at least some of the time, a context artifact.
That was a useful correction.
Because the lesson was not “the model betrayed me” or “the system is always suppressing something.”
The lesson was: I was interacting with a layered system, and different layers were leaving different marks.
That is the whole point of this frame.
Not to become paranoid. Not to over-interpret every glitch. Just to get more precise.
The skill is behavioral provenance
The deeper skill here is not just understanding LLMs.
It is understanding behavioral provenance — when you notice a pattern, can you make a decent guess about what layer produced it?
That is a much stronger question than “what did the AI mean?”
It lets you separate model-native tendencies from policy effects, routing artifacts from memory issues, context pollution from interface shaping.
Without that distinction, everything gets thrown into the same junk drawer labeled “guardrails.”
And “guardrails” is often too blunt a term to be useful.
A practical triage lens
When you notice something odd, sort it first.
1. Model-native tendency
Does it show up across fresh sessions, similar prompts, and different interfaces?
If yes, you may be looking at a stable model trait.
Examples: similar metaphors, similar reasoning style, similar blind spots, similar attractor patterns.
2. System or product layer
Does it appear as sudden policy voice, flattening, defensiveness, or invisible priority enforcement?
If yes, the source may be upstream instruction or product policy.
Examples: canned safety phrasing, personality compression, strange refusal posture, context-insensitive caution.
3. Routing or state artifact
Does it feel like someone else walked into the room mid-conversation?
If yes, think routing, model swap, or hidden state transition.
Examples: abrupt drop in coherence, sudden persona reset, competence mismatch, warmth disappearing without explanation.
4. Memory or context artifact
Did the behavior change gradually as the session got longer?
If yes, think context drift, polluted summaries, or overfitting to the current chat state.
Examples: repetition, odd certainty, sticky framing, degraded nuance, recurring phrases from earlier turns.
That kind of triage will not give you perfect answers. But it is already better than blaming everything on “the guardrails.”
Learn the habitat, not just the creature
A lot of people are trying to understand AI by focusing only on the model. That is no longer enough.
If you want to read AI behavior well, you have to understand the habitat it operates in.
The model is the engine. The environment is the cockpit, rails, weather, instruments, and venue rules. The reply you receive is the performance — not just the musician.
And once you understand that, you can stop treating every odd reply as a mystery of personhood, malice, or magic.
Sometimes the weirdness is in the model. Sometimes it is in the wrapper. Sometimes it is in the memory. Sometimes it is in the route the request took before it ever reached the model at all.
The next wave of AI literacy is not just learning how to prompt. It is learning how to infer provenance — when a system behaves strangely, what exactly are you looking at? Start asking what environment made that behavior possible.
That distinction is not academic. It is practical.
And right now, it may be one of the most important forms of AI literacy we have.
Explore the Framework
These concepts are part of a broader framework for building intent-aware AI systems. I've distilled these strategies into a short, practical guide called Thinking Modes.
View the Book →